
Big data testing
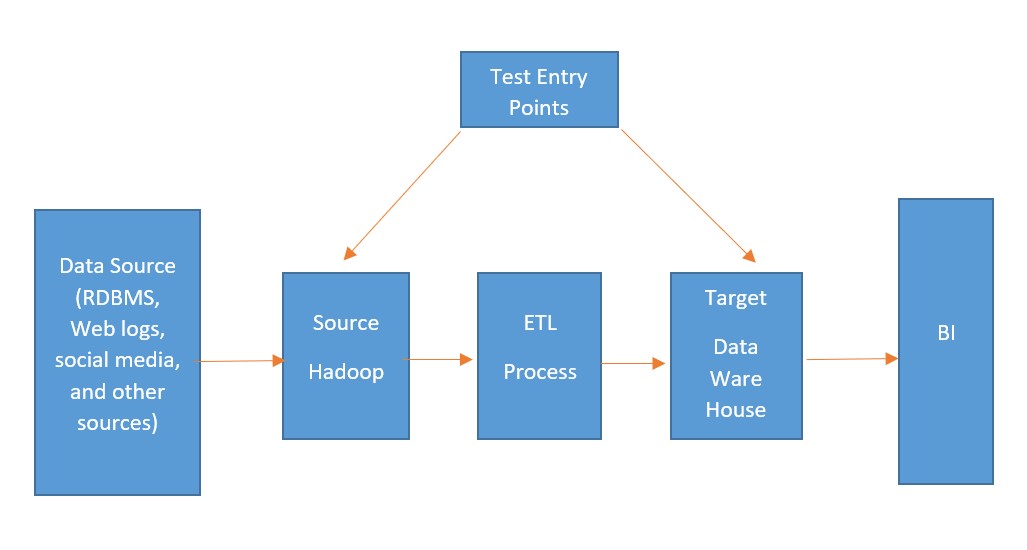
Big Data Testing is the process of verifying and validating the core functionalities of large-scale data applications. These applications deal with high volume, velocity, variety, veracity, and value across diverse domains such as insurance, banking, mutual funds, and security. Strong domain expertise and technical proficiency are crucial for ensuring accurate functional validation when dealing with massive data volumes.
Traditional computing methods fall short when handling such extensive datasets. That’s where Big Data Testing comes in—leveraging specialized tools, techniques, and frameworks to validate data pipelines, ensure seamless ETL operations, and maintain data integrity. The creation, storage, and analysis of data at this scale demand scalable solutions due to the complexity and speed involved.


")
